这篇是翻译文,自己感觉翻译比较乱,是来自searchengineland.com的文章,这个网站最近被google deindex,不知道啥回事
家里孩子正在哭闹,在哭闹中,我是硬着头皮翻译下去。没办法,孩子不让我抱,只能找点事情做,真烦心啊。
现在,有很多Google讨论群谈论关于Google爬虫如何工作的,在这里我们称为GB,这篇文章主要写关于google爬虫如何工作的
在过去的三个月里,GB总是很准时的来访问我的网站。
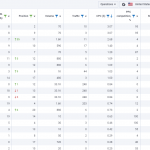
下面就是访问记录
[02/09/2018 18:29:49]: 66.249.76.136 /page1.html Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
[02/09/2018 19:45:23]: 66.249.76.136 /page5.html Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
[02/09/2018 21:01:10]: 66.249.76.140 /page3.html Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
[02/09/2018 21:01:11]: 66.249.64.72 /page2.html Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
[02/09/2018 23:32:45]: 66.249.64.72 /page6.html Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
有时候还有google其他bot:
[16/09/2018 19:16:56]: 64.233.172.231 /page1.html Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko; Google Search Console) Chrome/41.0.2272.118 Safari/537.36
[16/09/2018 19:26:08]: 66.249.69.235 /image.jpg Googlebot-Image/1.0
[27/08/2018 23:37:54]: 66.249.76.156 /page2.html Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.96 Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
我们从好几个方面来研究GB
抓取:观察GB如何抓取301重定向,爬图片以及canonicals
隐藏内容抓取:观察GB会不会抓取隐藏内容
如何生存以及爬:准备陷阱让GB跳进去
障碍物:我放了不同难度的障碍物来看GB如何处理
我建了一个关于提供航行在银河系里面还没有发现的星球的网站
个人觉得内容还是很优质但是都是胡说八道的
下面是网站结构图
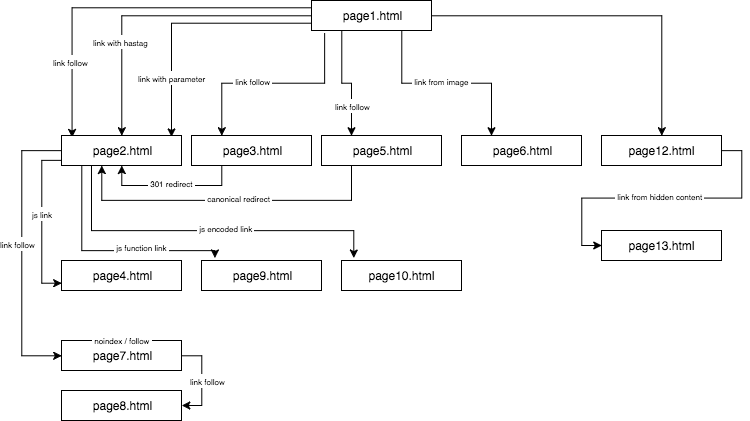
我提供原创内容,其他anchor/title/Alt都是原创的
这篇文章里面我就是用anchor 1来显示
Part1: First link counts
第一个实验我要做的就是GB爬取第一个链接原则,我们来看看是否被忽略以及如何对SEO影响
GB爬取第一个链接原则主要是说明GB只爬取文章里面的第一个链接 to a subpage。
如果我文章里面有两条链接指向同一个内容,根据规则,第二个链接以及Anchor会被忽视
这个问题被很多专家夸大,但是这个问题在很多商城上面呈现出来,因为导航会扰乱网站的结构
在一些独立购物站,我才用静态目录列表, 比如下图有4个主目录和25个副目录
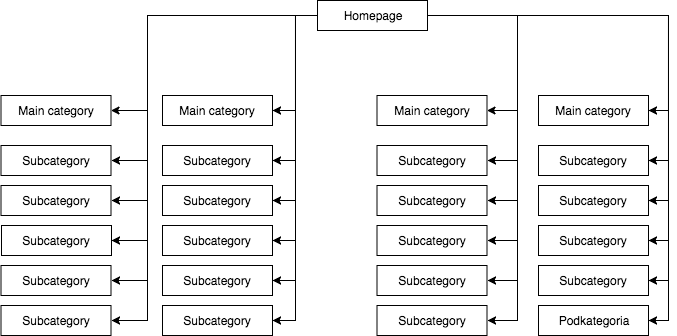
在这个网站结构图里,GB爬取所有链接,而且所有目录都是一样重要,那么权重自然就分散了
我个人看法就是,这个网站结构是错误的,不能这个布局一个网站目录
因为每个目录都是从首页链接进去,权重就是平均分,各占首页权重4%
以下图片就是比较合理的网站结构:
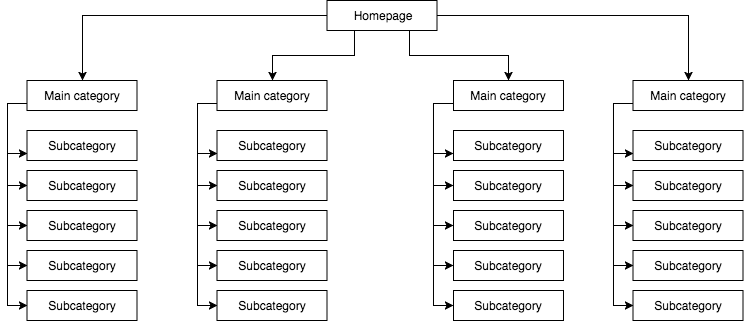
从上图来看,四个主图分别占首页权重25%,然后各自分散到各自的副目录
从GB first links counts rule,这个结构有利于内页被收录,比如说我写一篇文章链接到一个副目录,GB就会去爬取这个链接
我开始这个实验:
1. page1.html > page2.html,anchor 1
2. 在同一个页面,我加了一些元素来验证GB是否去爬取它们
我测试下面的方法:
- 我发一个外部链接来加速这个网页收录
- page1.html > page2.html,anchor 1 没有排名。大约等了45天,依然结果一样
对于一个网站来说,一个页面主题跟关键词相关,比这个关键词出现不相关页面里面,更容易得到排名
此外,page1.html包含anchor1排名比page2.html低,就是这个道理
page1.html包含anchor1,但是page2.html内容就是跟anchor1相关
以下就是我用四种方法来测试:
1. Link to a website with an anchor
< a href=”page2.html#testhash” >anchor2< /a >
GB爬取了page2.html/anchor2
虽然链接是page2.html, 但是链接导向page2.html#testhash 以及anchor2
不幸运的是,搜索testhash,没有排名
2. Link to a website with a parameter
page2.html?parameter=1
GB比较喜欢这种链接。 为了避免重复内容,anonical page2.html
从日志来看,GB爬了8次这个链接,但是两周后,GB访问下降了
同时,page2.html / anchor 3 没有被收录
从Search Console,page2.html链接不存在,但是anchor3存在
3. Link to a website from a redirection
为了强制GB爬取网站,我 page1.html anchor 4 导向page3.html > 301跳转到 page2.html
45天后,page2.html在anchor 4没有排名
但是anchor4 关键词被收录了
4. Link to a page using canonical tag
< link rel=“canonical” href=”https://example.com/page2.html” />
page1.html anchor5 指向 page5.html,而且page5.html是原创内容但是canonical tag to page2.html ,如上
结果呢,page5.html 被收录了即使canonical tag to page2.html
但是,page5.html没有排名
从这一点来说,GB完全忽视canonical tags。
所以说,用rel=canonical没法避免一些网页被收录
part2 Crawl budget
JavaScript link with an onclick event
< a href=”javascript:void(0)” onclick=”window.location.href =’page4.html’” >anchor6< /a >
GB爬取page4.html,收录这个页面,但是查询anchor6, 依然没有排名
从这一点来说,GB可以爬取JavaScript link以及收录此链接,但是没有传递权重
Javascript link with an internal function
< a href=”javascript:void(0)” class=”js-link” data-url=”page9.html” >anchor7< /a >
依然没有作用
JavaScript link with coding
< a href=”javascript:void(0)” class=”js-link” data-url=”cGFnZTEwLmh0bWw=” >anchor8< /a >
用base64 algorithm来显示,结果就是谷歌无法收录,这是不用rel=nonfollows来避免Google收录网页内容
Part 3: Hidden content
我在网页内容里面hidden content添加了page12.html/anchor9,Google收录了,同时搜索anchor 9 居然有排名
hidden content 是用Cascading Style Sheets 模块来隐藏,而且添加了一个按钮 show more button, 隐藏内容里面添加page12.html/anchor9
从这一点可以看出,GB是可以看到你在网站隐藏的标签,同时传递权重
综上所述,通过links with parameter, 301 redirects, canonicals, anchor links不可能越过First Link Counts Rule。同时,是有可能用Javascript links来建网站结构来摆脱First Link Counts Rule的限制。再者,GB可以爬取隐藏内容的以及收录此内容,传递权重。